トピックモデルは複数の文書データに共通のトピック群を探す手法で、文章の中で言語的に固定された単語や意味カテゴリではなく、複数の単語の共起性によって創発される潜在的意味を抽出してくれます。今回は、トピックモデルの入力となる文書データが粗視化されている意義について、またハイパーパラメタという概念がLDAの中でどのような位置付けなのかということを、SEEDATA Technologiesの広本と鳥居が説明していきます。
(1)分析の対象に合わせた情報の粗視化
トピックモデルにおいては、文章は単語の集合(Bag of words)として扱われ、単語の順序は解析する情報として含まれていません。また段落、一文といった概念も無いので、これはn-gramなどと比べて、潜在的意味を明らかにしたいという目的に対しては、分析の粒度が粗いように見えるかもしれません。
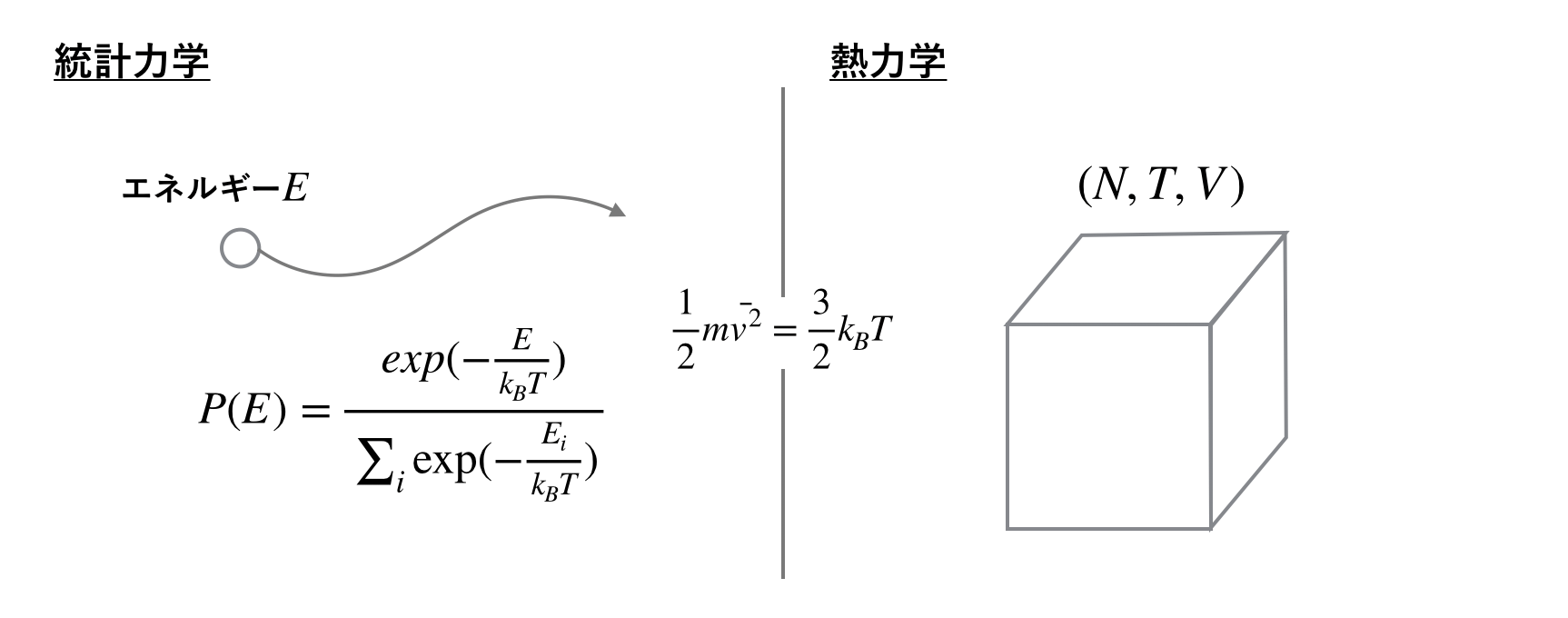
しかしトピックモデルに限らず、情報を粗視化することや、要素を一様に扱うといった近似は、計算時間の短縮以上に意味のあることなのです。物理を例に考えてみましょう。あらゆる事象を最小単位まで分割して考えてメカニズムを明らかにしようとする要素還元論的立場に立てば、気体の運動を平均的に扱って論を展開する熱力学はこの考えに反します。しかし実際、熱力学はマクロスコピックな熱の移動や物質の輸送に関しての予言や分析において強力なツールとなっています。対して、気体分子を1つ1つあらわに扱う統計力学は、ミクロな現象に対しては強力ですが、たとえば系全体の変化を考えた時には、熱力学の方が系全体の性質を捉えやすいことがあります。つまり、観察したい対象や目的によって、分析の細かさも柔軟に変える必要があるのです。
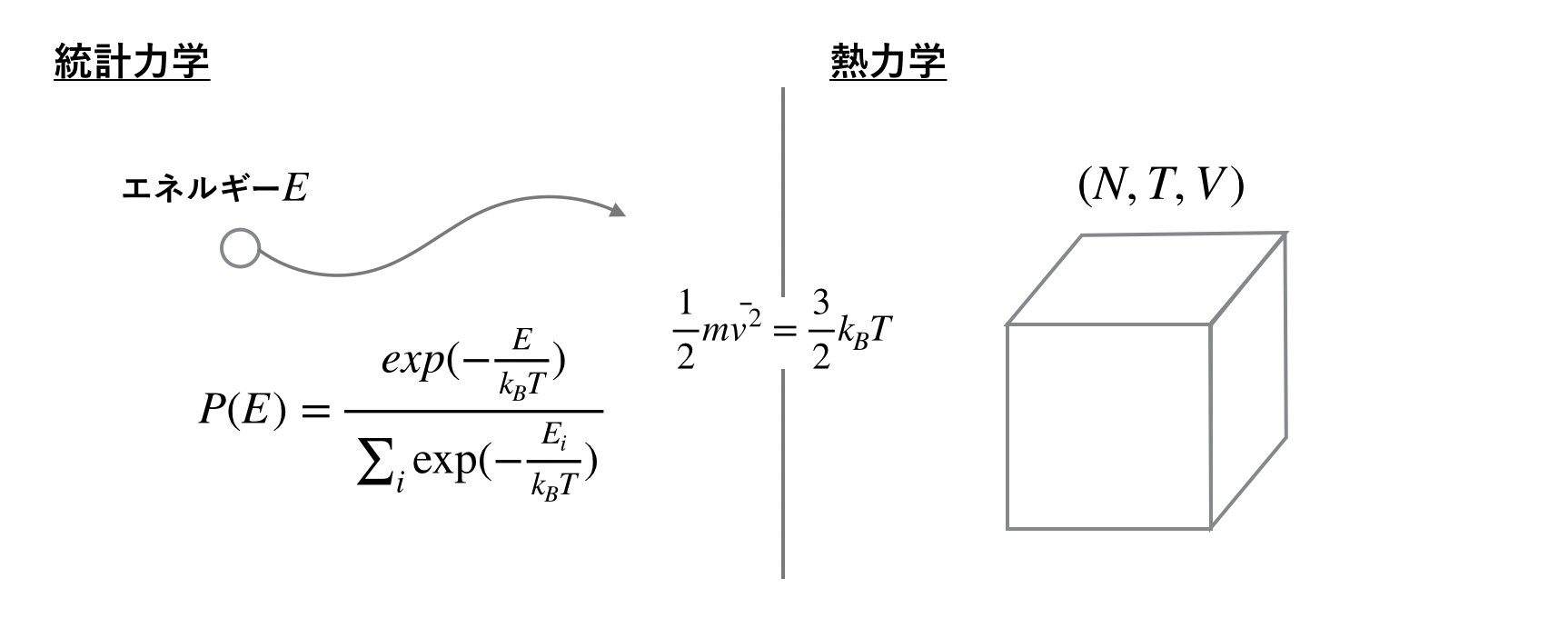 トピックモデルについて考えてみると、そもそもの目的は文書データの潜在的意味の抽出と、それらに基づいたクラスタリング、文書間の意味相関の理解と設定できるでしょう。この場合、1つの文書を細かく分析するのでは無くて、文書データ全体の中での相対的な意味をマッピングすることを目指しているので、1つ1つの文章に対する分析の粒度はそこまで高くなくてよいはずです。むしろ文書データをある程度粗視化し、その輪郭が分かる程度までに情報を圧縮しなければ、計算機にとっても人間にとっても分類するのは難しく、情報が多すぎると人間が直感的に理解できるレベルで綺麗に分かれない可能性があります。実はLDAにおいては、ハイパーパラメタαが文章データの在りようを一度に把握できる地図になっているのです。
トピックモデルについて考えてみると、そもそもの目的は文書データの潜在的意味の抽出と、それらに基づいたクラスタリング、文書間の意味相関の理解と設定できるでしょう。この場合、1つの文書を細かく分析するのでは無くて、文書データ全体の中での相対的な意味をマッピングすることを目指しているので、1つ1つの文章に対する分析の粒度はそこまで高くなくてよいはずです。むしろ文書データをある程度粗視化し、その輪郭が分かる程度までに情報を圧縮しなければ、計算機にとっても人間にとっても分類するのは難しく、情報が多すぎると人間が直感的に理解できるレベルで綺麗に分かれない可能性があります。実はLDAにおいては、ハイパーパラメタαが文章データの在りようを一度に把握できる地図になっているのです。
(2)全文章データを代表する量としてのハイパーパラメタ
これまで、ハイパーパラメタの振る舞いについて多く考察を行なってきましたが、より定性的な議論からその正体について考えてみたいと思います。トピックモデルの世界観は、単語の集合からなる複数の潜在的意味(トピック)があらかじめ決まっており、そこを発信源として単語が確率的に飛び出し、一つ一つの文章が生成されるというものです。

このときハイパーパラメタとは、単語の飛び出し方、文章の生成過程を決定するパラメタとなります。このベクトル1つから、数千、数万の文章群が生成されているという仮定を置いているのです。つまり、ハイパーパラメタさえ決まれば、文章データ全体がどのように分布しているのかが分かります。このマップの読み方と最適なパラメータは、以前考察を行った通りです。
大切な点は、ハイパーパラメタが全ての文書データに一様に用いられる量だということです。以下の式は、サンプリング時に各文章で用いられる式です。dは文章、kはトピックを指定する添字です。

これを見ると、各文章に対して同じαを用いていることが分かります。文章は一つ一つ違うものなので、一見、無理のある式に見えるかもしれません。しかし、この定式こそ、αにあらゆる情報が収斂されるための仕掛けになります。これがもし、各文章ごとに異なるハイパーパラメタが設定されているとしたらどうなるでしょうか。文書の生成は文章ごとでローカルに閉じた現象となり、文章間の意味や全体像の把握は不可能になります。
LDAの中で、ハイパーパラメタのみが唯一、全ての文章データに対し一様に登場し、全ての文章と微弱ながらも相関を持つ、文章集合を代表する指標なのです。サンプリングとは、全ての文章に触れさせながら、ハイパーパラメタを丁寧に育てるプロセスだと言えるかもしれません。
【この記事の作成者】
鳥居健次郎、広本拓麻:SEEDATA Technologies
【参考文献】
自然言語処理シリーズ8 トピックモデルによる統計的潜在意味解析, 奥村学著,コロナ社
↓↓SEEDATAの無料ホワイトペーパーができました↓↓

新規事業を立ち上げの際に担当者が陥りがちな失敗を項目ごとに解説(全25ページ・493KB)