
トピックモデルは複数の文書データに共通のトピック群を探す手法で、文章の中で言語的に固定された単語や意味カテゴリではなく、複数の単語の共起性によって創発される潜在的意味を抽出してくれます。このページではSEEDATA Technologiesの広本と鳥居が、トピックモデルにおけるハイパーパラメタの解釈について説明していきます。
(1) ディリクレ分布について
トピックモデルでは、文書のトピック分布およびそれぞれのトピックの単語分布を生成する分布としてディリクレ分布を仮定しています。そして、ディリクレ分布のパラメタとして与えられるのがハイパーパラメタです。例えば、ハイパーパラメタがすべての要素が1の3次元ベクトルとして与えられたとき、ディリクレ分布を3次元の単体上にサンプリングすると以下のような分布が得られます。
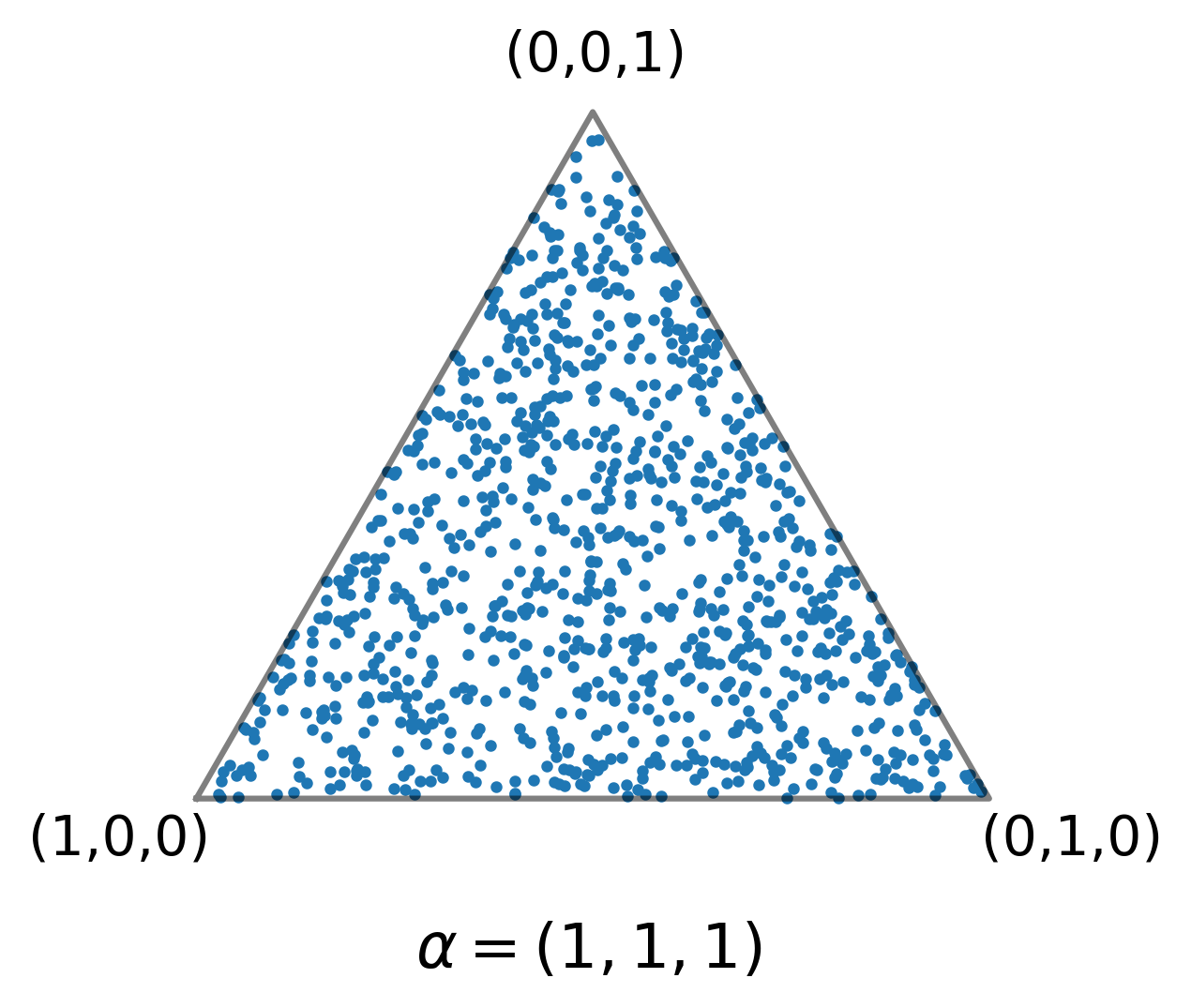
上の図からディリクレ分布が単体上に一様に分布していることが分かります。これを三面サイコロの出る目の確率分布として見ると、まだどの目が出やすいかが不確定な状態でサイコロの形について全く分からないことがわかります。これは、ハイパーパラメタがディリクレ分布の仮想的頻度を表しており、この場合ではそれぞれの目が一回ずつ出た状態と解釈できるためです。このことからalpha = (100, 100, 100)の場合では、サイコロの目の出る確率が等確率に近づくことは容易に想像できると思います。
■ LDA(Latent Dirichlet Allocation)の意味
トピックモデルで広く使われているのがLDAという文書の確率的生成モデルです。LDAは、各文書には潜在トピックという観測できない確率変数があると仮定し(Latent:潜在的)、さらにその潜在トピックの分布がディリクレ分布によって生成されると仮定し(Dirichlet:ディリクレ分布)、その生成されるトピック分布がK(トピック数)次元の単体上に”配置”されること(Allocation:配置)を表している。これがLDAと呼ばれる所以です。上の図のように3個のトピックで生成される文書を考えると、単体上の点一つ一つが各文書を表していることになります。これは、文書のトピック分布とその文書自体が一対一で対応しているからです。
(2)ハイパーパラメタの解釈
このようにハイパーパラメタはディリクレ分布の仮想的頻度として解釈されますが、これを文書に対するトピックモデルではどう解釈すればよいのでしょうか。私たちは、ハイパーパラメタを解釈する上で文書間のトピック分布の多様性と各文書内のトピックの多様性の2つの要素に着目しました。文書間で多様性があるとは、文書ごとに異なるトピック分布(話題)を持つことを表しています。ハイパーパラメタの値がすべて1のときにこの多様性が最大となることは上の図を見れば分かると思います。一方で文書内で多様性があるとは、その文書が一つのトピックでは表現できず、複数のトピックによって構成されている文書であることを表しています。例えば、ある文書集合が3つのトピック(スポーツ、ゲーム、ビジネス)によって生成されると考えます。このとき、文書内で多様性があることは、その文書がeスポーツやスポーツビジネスなど複数のトピックによって構成されていることに対応します。
今回はこの2点に着目しながら、文書のトピック分布を生成するディリクレ分布のハイパーパラメタalphaについて、(a) ハイパーパラメタの値の大きさ、(b) 各要素同士の相対比、という2つの視点で最適なハイパーパラメタについて考察します。以下では、簡単のためにトピック数を3として考えます。このとき、ハイパーパラメタalphaは3つの要素を持つベクトルで、それぞれの要素がそれぞれのトピックの仮想的頻度に相当します。
また、視覚的な理解を促すためにそれぞれのトピックに3色(RGB)を対応させ、ディリクレ分布によって生成された各トピックの確率をそれぞれの色の強度と考えることにします。例えば、(0.4, 0.3, 0.3)、(0.2, 0.3, 0.5)、(0.7, 0.2, 0.1)という確率分布が得られた場合、それぞれの確率分布に対応する色は下のようになります。
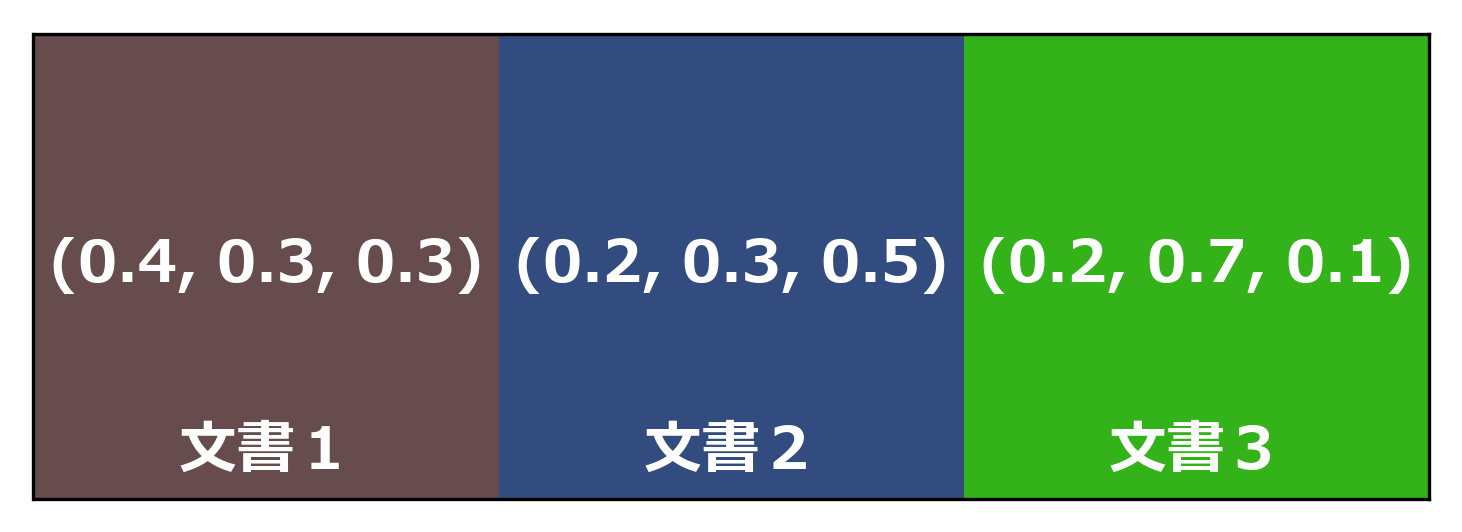
さらに、これはあるディリクレ分布から3つの文書に対してトピック分布を生成し、その分布に対応する色を左から塗ったものと考えることもできます。先程の例を使い、赤:スポーツ、緑:ゲーム、青:ビジネス、というように色とトピックを対応させればより理解しやすいと思います。例えば上の図で、文書1:eスポーツビジネス、文書2:スポーツゲームの市場、文書3:ゲームマー、という具合に色とトピックを対応させることができます。様々なハイパーパラメタに対してディリクレ分布からサンプリングを行い、上のように可視化すれば、どのようなハイパーパラメタ(各要素の大きさ、トピック数)がトピックモデルにおいて最適であるかの議論がしやすくなります。
(a) ハイパーパラメタの値の大きさ
先にも述べましたが、ハイパーパラメタの値は仮想的頻度を表しています。仮想的頻度はそのトピックがでる”確からしさ”を表しているので、その値が大きいほどある定まったトピック分布(例えば、一様分布)が生成される確率が高くなることが分かります。実際に、値の大きさが変化したときディリクレ分布がどう変化するか見てみましょう。

これは、すべての要素が同じ値のハイパーパラメタで、その値の大きさを変化させたときの1000回サンプリング結果です。上の図において、一つ一つの点が各文書のトピック分布を表し、その色でトピック分布の性質を表現しています。文書間の多様性に関して見ると、すべての要素が1のときに最大となり、1から遠ざかるほど小さくなりそうです。一方で、文書内の多様性については、値が大きいほど大きくなりそうです。これをグラフにまとめてみましょう。ハイパーパラメタの値の大きさによって文書集合の性質を測れることがわかります。
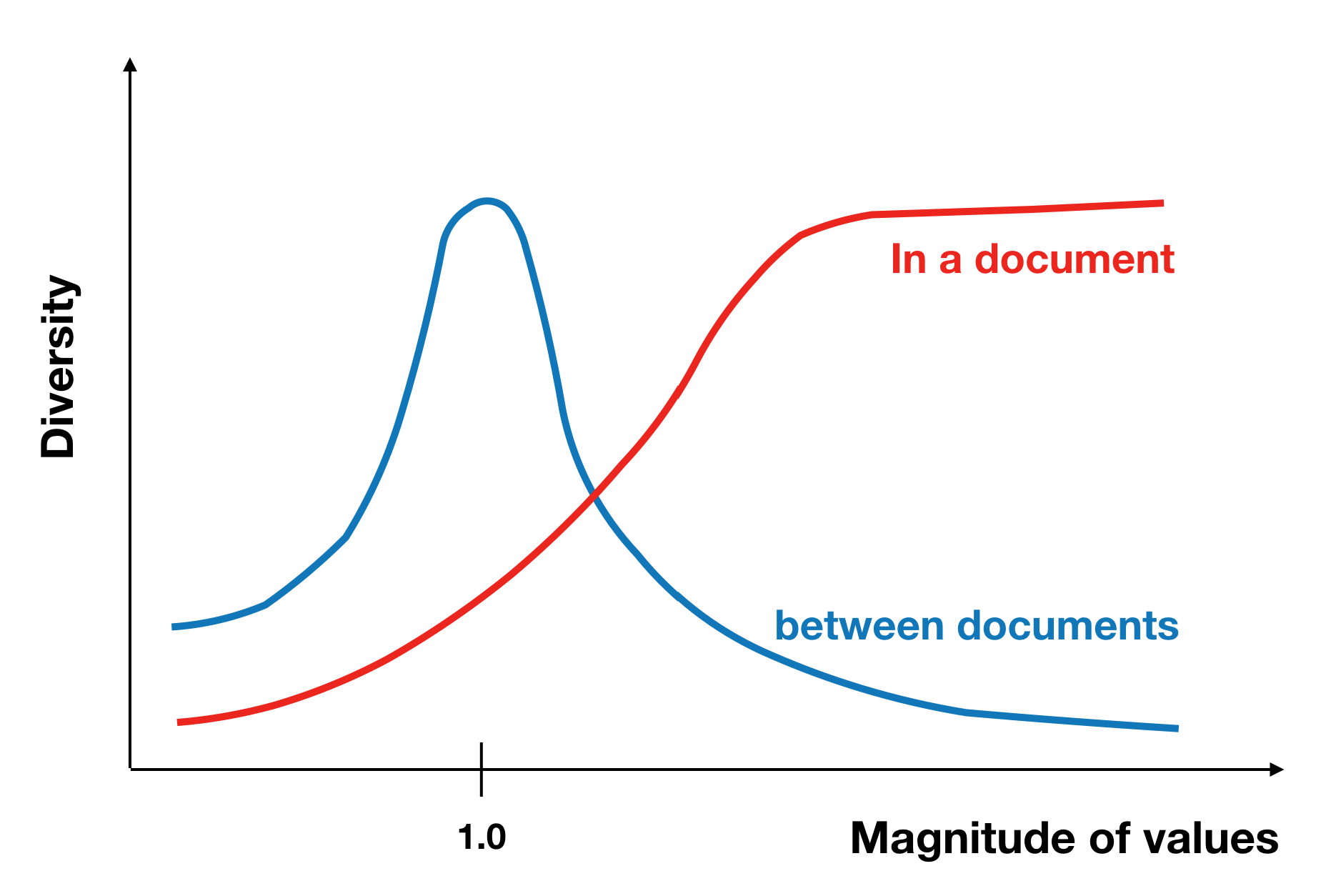
次に、それぞれのハイパーパラメタをもとに文書のトピック分布をサンプリングして、それぞれの文書がどのようなトピック分布を持ち、それが文書間でどれくらい変化しているのかを視覚的に理解しましょう。下の図は、20個の文書に対してそれぞれのハイパーパラメタでトピック分布を生成し、そのトピック分布に対応する色を塗って20個の文書を左から並べたものです。

ハイパーパラメタの値が小さい場合は、どれか一つのトピック(赤or青or緑)が強い分布になっており、全文書を通して3つのトピック分布のみが現れていることがわかります。値が1の場合は、様々なトピック分布があり、文書ごとにその分布も異なっていることがわかります。値が大きい場合では、どの文書も同じトピック分布を持ち、その分布はどのトピックも同じ割合で含んでいることが分かると思います。
(b) 各要素同士の相対比
次に、ハイパーパラメタの要素の相対比について考えます。これは単純で、値の大きい要素のトピックほどトピック分布に占める割合が大きくなるだけです。下図に、相対比を変えたときのサンプリング結果を示します。

alpha が(1, 1, 1) → (1, 2, 4) → (1, 5, 15)と相対比が大きくなるにつれて、トピック分布は値が大きいトピック(この場合は青色)を多く含むようになります。
(3)最適なハイパーパラメタの直感的な理解
これまで、文書内と文書間の多様性に着目して、ハイパーパラメタの値の大きさと各要素同士の相対比という2つの視点からトピックモデルにおけるハイパーパラメタの考察を行ってきました。それでは、トピック分布の生成過程として最適なハイパーパラメタはどのような性質を持ったものなのでしょうか。縦軸にハイパーパラメタの値の大きさを、横軸に各要素同士の相対比をとり、9つの異なるハイパーパラメタについてサンプリングを行った結果を並べて、どれが直感的に最適か見てみましょう。

直感的には、文書間である程度の多様性を保ちつつ、文書内でのトピック分布がある程度偏った分布となるのが最適なのではないかと考えられます。上の図だと、(0.1, 0.2, 0.4)、(0.1, 0.5, 1.5)あたりのハイパーパラメタがそれに当たります。これをまとめると、次のようになります。
- ハイパーパラメタの値が0.1 ~ 5の範囲にある。
- 各要素の相対比が大きすぎない。
この2つを満たすものが最適なハイパーパラメタといえるのではないでしょうか。
今回は、トピックモデルにおいてハイパーパラメタがどのような意味を持つのかについて考察しました。次回は、実際の文書データを使って、この考察が妥当かどうか検証したいと思います。
【この記事の作成者】
鳥居健次郎、広本拓麻:SEEDATA Technologies