
トピックモデルは複数の文書データに共通のトピック群を探す手法で、文章の中で言語的に固定された単語や意味カテゴリではなく、複数の単語の共起性によって創発される潜在的意味を抽出してくれます。このページではSEEDATA Technologiesの広本と鳥居が、トピックモデルの使用例とサンプリング時の注意点やハイパーパラメタの解釈について説明していきます。
(1) 実際の文書データに対するトピックモデルの適用
■分析対象
今回は、SEEDATAがこれまで社内で共有したニュース6000件の本文を対象とし、鳥居が周辺化ギブスサンプリングに基づいてNumpyから実装したアルゴリズムを用いて分析を行いました。トピック数は25とし、イテレーションを30回として潜在変数をサンプリングしています。
■分類結果
例えばトピック1を見てみましょう。それぞれのトピックに対して、出現確率の高い順に単語を並べています。
トピック 1: ['研究', '健康', '患者', '医療', '治療', '実験', '効果', '医師', '人類', '検査', '人間', '病院', '結果', '記憶', '研究者', '運動', 'トレーニング', '状態', '病気', '論文']構成している単語を見てみると、健康や医療がトピックであると類推できます。
次にトピック7を見てみると
トピック7: ['データ', '開発', '技術', '人間', 'システム', 'テクノロジー', '活用', '分析', 'チーム', '分野', '人工知能','実現', '課題', '領域', '事業', 'ビジネス', 'イノベーション', '組織', 'マーケティング', '重要']データ、テクノロジーという単語から、まさにこのデータ分析技術や機械学習についてのトピックであるということが分かります。LDAに基づくトピックモデルの世界観が、実際のニュースの集合に対しても適応できることが確認できました。次に、サンプリングに必要なステップ数について考えていきます。
(2)トピックの収束性
■ステップに対するハイパーパラメタの振る舞い
ギブスサンプリングはメトロポリス・モンテカルロ法の一つで、生成過程を仮定することで初期条件から確率的に変数や状態を遷移させ、定常的な確率分布を再現する手法です。トピックモデルの周辺化ギブスサンプリングにおいては、潜在変数のサンプリングのために、トピックの仮想的頻度を初めに決めておく必要があります。これはハイパーパラメタと呼ばれ、イテレーションの各段階において対象とする潜在変数を事後分布に従って生成するためです。
つまり、最終的に潜在変数やトピックについて定常分布が得られるようにするためには、ハイパーパラメタがある値に収束する必要があります。上記の分析において、25次元ベクトルのハイパーパラメタがステップに対してどのように変化しているのかを見てみましょう。縦軸には、L2ノルムを表示しています。
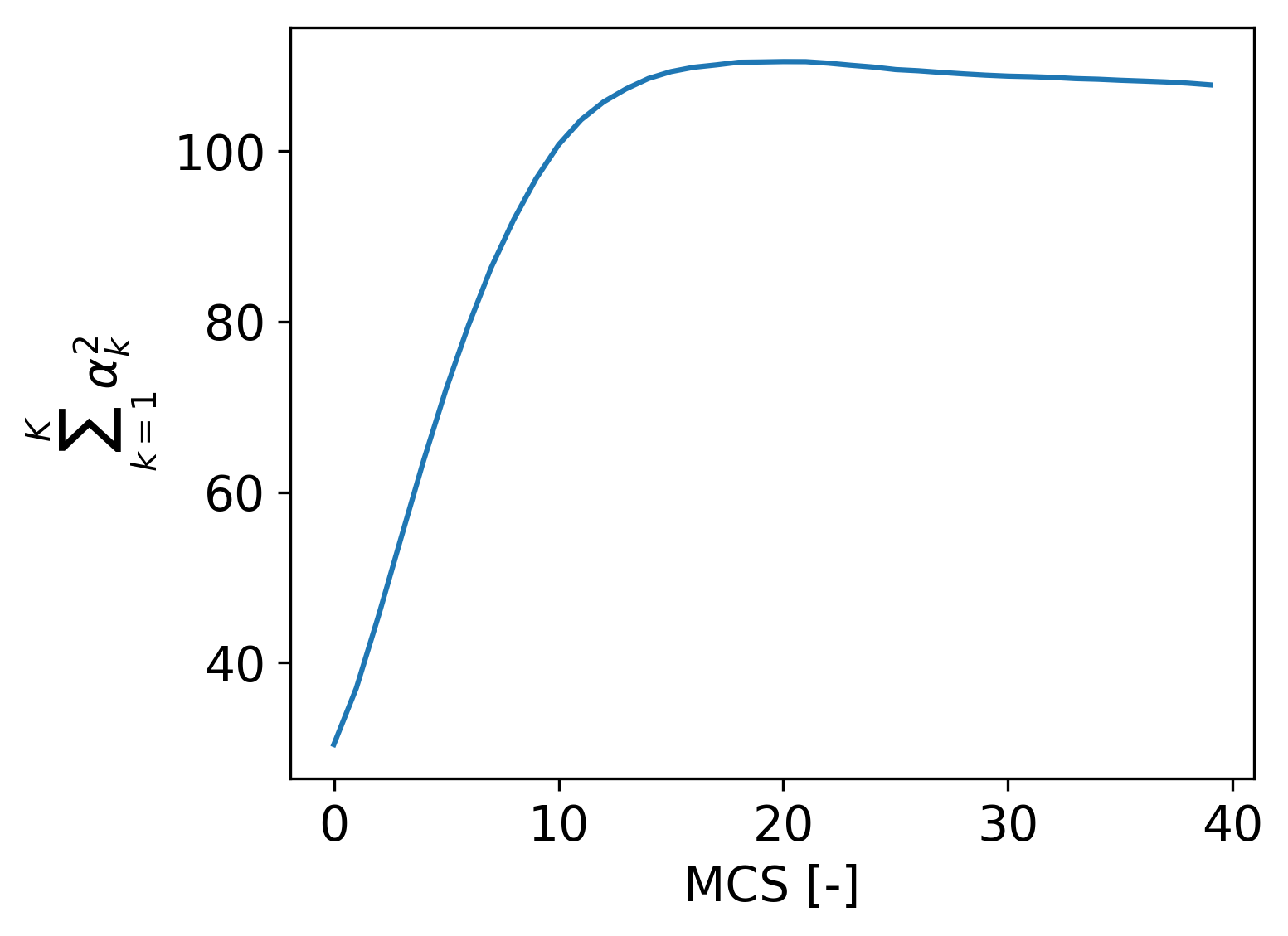
横軸のMCS(=モンテカルロステップ)は、全ての潜在変数についてディリクレ分布から生成したところを1MCSとしてカウントする単位です。この結果を見ると、20MCSからハイパーパラメタのL2ノルムがほとんど変化していないことから、これ以降はほぼ定常分布になっていることがわかります。
■トピックの初期値依存性
メトロポリス・モンテカルロ法は初期値によらず一定の分布を再現するはずなので、異なる初期値に対しても同様にステップ依存性を確認します。以下は、4つの異なるハイパーパラメタに対し、そのL2ノルムを図示したものです。
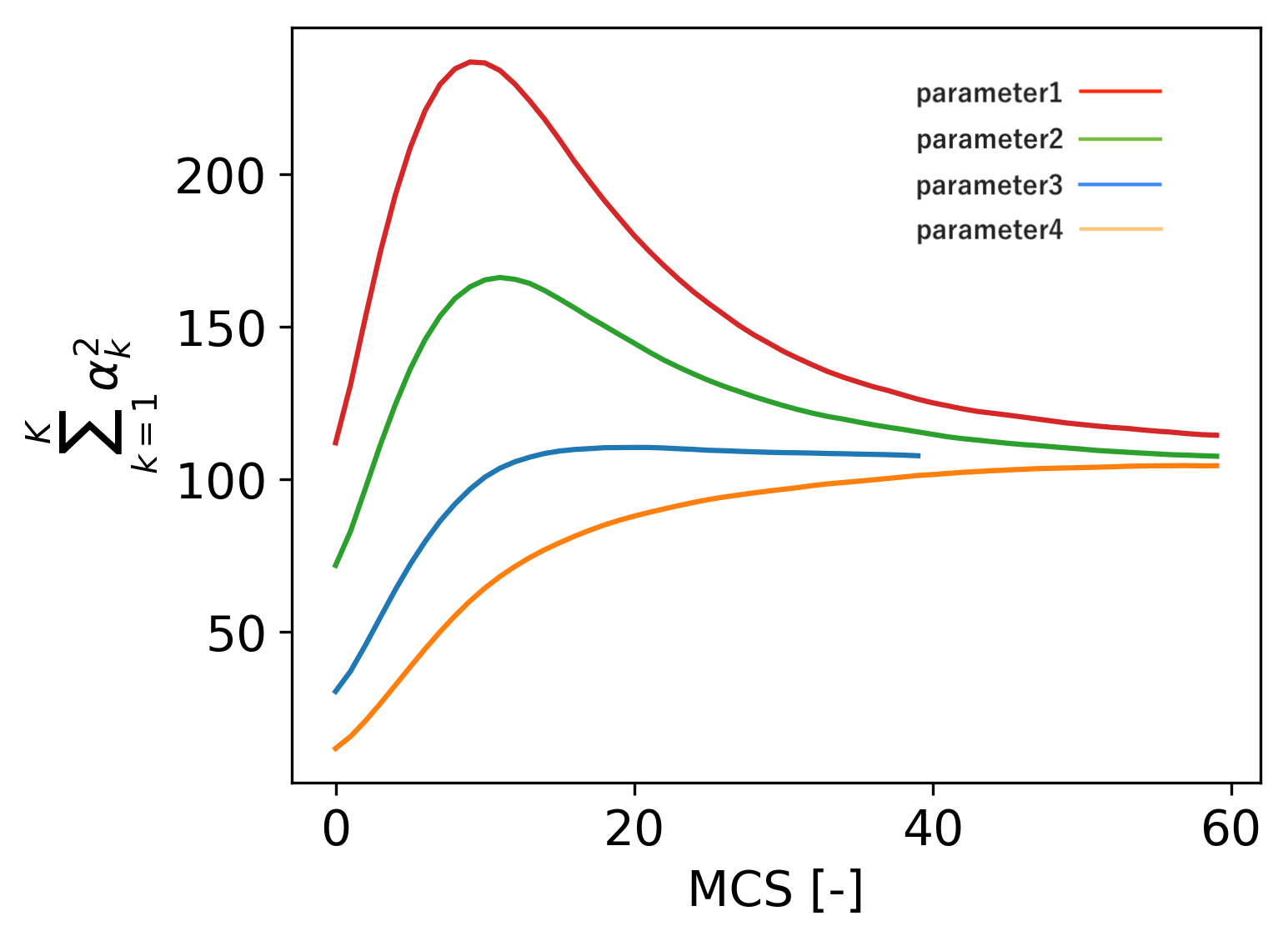 ここで縦軸を仮にL1ノルムとすると、成分の単純和が等しいとしてもベクトルの各成分の比が異なっている場合があるため、今回は成分ごとの違いを過大評価するようなL2ノルムを用いています。このグラフから、異なる初期値に対してもほとんど同じ値に収束しており、従って異なる初期値に対しても同じようなトピック分布を再現することが分かりました。実際、上の図でparameter2とparameter3のトピックを比較してみると、
ここで縦軸を仮にL1ノルムとすると、成分の単純和が等しいとしてもベクトルの各成分の比が異なっている場合があるため、今回は成分ごとの違いを過大評価するようなL2ノルムを用いています。このグラフから、異なる初期値に対してもほとんど同じ値に収束しており、従って異なる初期値に対しても同じようなトピック分布を再現することが分かりました。実際、上の図でparameter2とparameter3のトピックを比較してみると、
青のトピック 1: ['研究', '健康', '患者', '医療', '治療', '実験', '効果', '医師', '人類', '検査', '人間', '病院', '結果', '記憶', '研究者', '運動', 'トレーニング', '状態', '病気', '論文']緑のトピック 10: ['研究', '健康', '患者', '医療', '治療', '医師', '効果', '睡眠', '病院', '運動', '検査', '病気', '実験', '記憶', '状態', '人工', '結果', '遺伝子', '原因', '身体']このように、トピックを構成する単語の出現確率は若干異なるものの、同じ「健康・医療トピック」を発見することができました。次回は、今回収束性が確認されたハイパーパラメタが、トピックモデルにおいてどのような意味を持つのかについて考察したいと思います。
【この記事の作成者】
鳥居健次郎、広本拓麻:SEEDATA Technologies
↓↓SEEDATAの無料ホワイトペーパーができました↓↓

新規事業を立ち上げの際に担当者が陥りがちな失敗を項目ごとに解説(全25ページ・493KB)