[mathjax]
はじめに
データマイニング・機械学習における最もシンプルな分析手法である線形回帰について説明します。この記事では線形回帰を例に、データマイニングの基礎概念である尤度関数について学びます。データマイニングとは、データから意思決定を高度化する仮説的役割を担う知識を抽出する作業のことです。
データマイニングと機械学習の違いについては次の記事をご覧ください。
最小二乗法
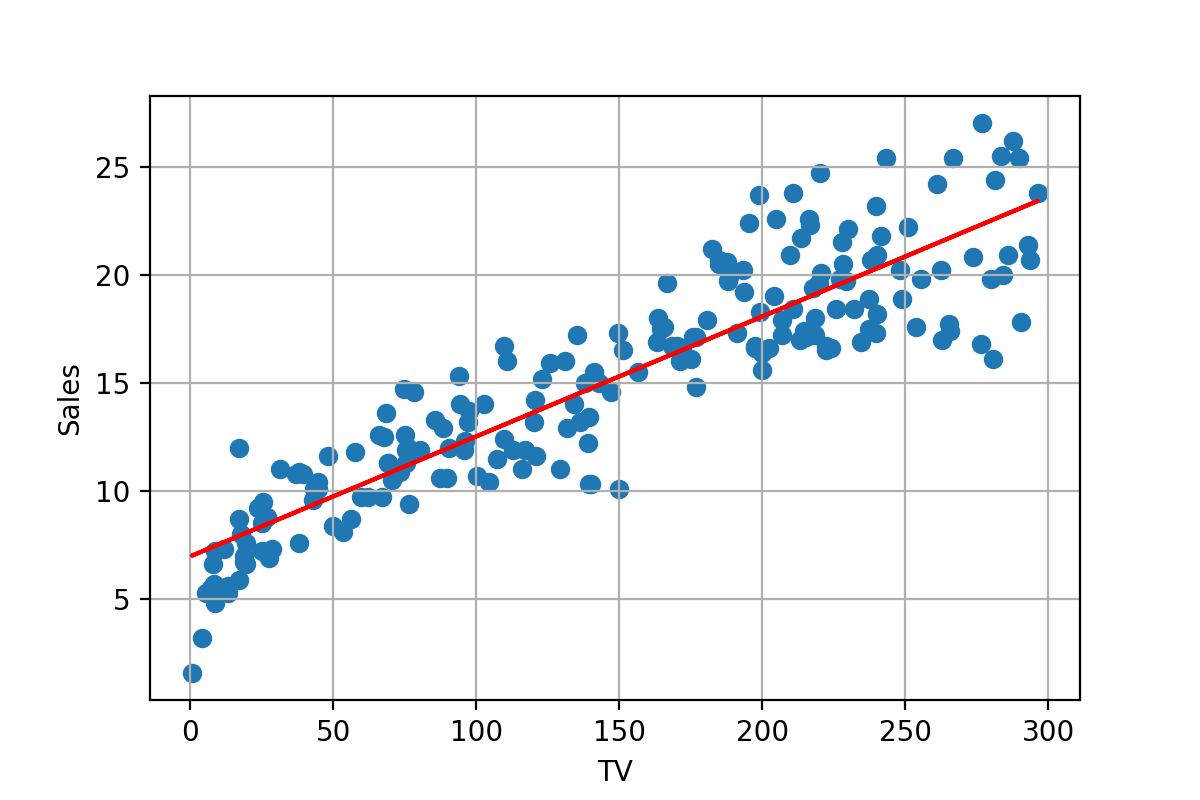
まずは簡単な例として、TV広告費と売り上げの関係に関する次のデータをご覧ください。
なお、データは次のウェブサイトよりcsvをダウンロードできます。


予算割り当ての意思決定に活用するため、TV広告費と売り上げの関係を大まかにモデリングしたいとします。直感的には、グラフを見ると概ね直線的な相関関係が見えますから、一次関数でモデリングしてみましょう。次の図のようなイメージです。

TV広告費を(x_1)、売り上げを(y)とし、各データ点を({x_1^{(i)}, y^{(i)} }_{i=1}^N)と表記します(サンプルサイズ=(N))。さらに、売り上げの値(y)をTV広告費(x_1)を用いてモデリングする関数を(h_theta)とすると、次のような表記ができます。(h)はhypothesis function(仮説としての関数)を指し、添字の(theta)はモデルのパラメタが(theta)であることを示します。
$$
large
begin{align}
h_theta(x) &= theta_0 + theta_1 x_1 \
&= theta_0 x_0 + theta_1 x_1 \
&= theta^mathrm{T} x \
end{align}
$$
補足
上記の変数表記は、米国のAI研究で第一人者であるAndrew Ng氏が採用している記法に基づきます。Andrew Ng氏は機械学習の有名なコースであるCourseraのMachine Learningを担当する先生であり、Coursera立ち上げメンバーの一人でもあります。
ここで、(x_0)という新たな変数が導入されているのは、(h_theta(x)=theta^mathrm{T} x)という線形の表記を可能にするためです。(x_0)は常に(x_0=1)を満たすとします。また、(theta=(theta_0, theta_1)^mathrm{T})、(x=(x_0, x_1)^mathrm{T})というベクトル表記をしていることに注意してください。
さて、売り上げをモデリングするパラメタである(theta)はどのように決めたら良いでしょうか。その一つとして、実測値とモデルによる推定値の差(残差)の2乗の合計を最小化することによりパラメタを決定する最小二乗法が挙げられます。
$$
large
hat{theta} = argmin_theta sum_{i=1}^N (y^{(i)}-h_theta(x^{(i)}))^2
$$
(hat{theta})は推定された(theta)であることを、(argmin_theta)は(argmin)以下を最小化するような(theta)のことを示します。最小化する関数(コスト関数)が分かれば、線形回帰の場合は偏微分がゼロになる点を解析的に求めたり(正規方程式)、数理最適化の技術(勾配法)を使用してモデルのパラメタを求めたりすることが可能です。今回の記事では、最適化の技術には立ち入りません。
最尤推定
さて、今回の記事のメインポイントはここからです。「なぜ最小二乗法なのか」を、モデリングと確率の観点で導出していきましょう。先ほど、「おおむね直線的な相関関係にある」と仮定しましたが、これをもう少し具体的に次のようにモデリングしてみましょう。
$$
large
begin{align}
y^{(i)} &= theta^mathrm{T} x^{(i)} + epsilon^{(i)} \
epsilon^{(i)} &sim mathbb{N}(0, sigma^2)
end{align}
$$
ポイントは、正規分布にしたがって生成される(epsilon^{(i)})です。誤差項と呼びます。「一次関数と、正規分布にしたがって生成される誤差項の和によってデータが生成される」という仮説をモデリングします。注意しなくてはならないのは、この式が「データの真の生成過程を示すものではない」ということです。これはデータの生成過程の仮説をモデリングしたものに過ぎません。この仮定がどの程度妥当なものであるかは、モデルのパラメタを決定した後に、モデル選択として評価する必要があります。
さて、「データ(D)を生成するモデルとして、パラメタ(theta)により定義される確率分布を仮定したときの、データの尤もらしさ」として次のような量を定義します。
$$
large
L(theta) = p(D|theta) = p({x^{(i)}, y^{(i)}}_{i=1}^N|theta)
$$
これを尤度(likelihood)、または(theta)の関数であることを強調して尤度関数と呼びます。この尤度関数を最大化するようにモデルのパラメタ(theta)を決定するのが最尤推定です。
誤差項である(epsilon^{(i)})が各サンプルごとに独立に生成するという独立同分布の仮定をおくと(iid, independent and identically distributed)、尤度関数は次のように展開できます。
$$
large
L(theta) = p({x^{(i)}, y^{(i)}}_{i=1}^N|theta) = prod_{i=1}^N p(y^{(i)}|x^{(i)}; theta)
$$
重要
なお、(p(y^{(i)}|x^{(i)}; theta))という表記に注意してください((p(y^{(i)}|x^{(i)}, theta))ではない)。これは(y)の(x)に対する条件付き確率であり、それがモデルパラメタである(theta)の関数であることを示します。最尤法においては、(theta)は確率変数としてモデリングされていないので、(y)の(x)に対する条件付き確率において、(theta)は(y)と確率的な依存関係にはありません。
さて、総乗は計算上の都合が悪いので、対数をとって総和に変換します。よって以下のような対数尤度関数を最大化します。
$$
large
l(theta) = log L(theta) = sum_{i=1}^N log p(y^{(i)}|x^{(i)}; theta)
$$
(epsilon)が正規分布に従い、確率密度関数が次のように与えられることに注意すると、
$$
large
p(epsilon) = frac{1}{sqrt{2pi}sigma}exp(-frac{epsilon^2}{2sigma^2})
$$
尤度関数は次のように展開できます。
$$
large
begin{align}
l(theta) &= sum_{i=1}^N log p(y^{(i)}|x^{(i)}; theta) \
&= sum_{i=1}^N log frac{1}{sqrt{2pi}sigma}exp(-frac{(y^{(i)}-theta^mathrm{T} x^{(i)})^2}{2sigma^2}) \
&= Nlogfrac{1}{sqrt{2pi}sigma} – frac{1}{2sigma^2}sum_{i=1}^N (y^{(i)}-theta^mathrm{T} x^{(i)})^2
end{align}
$$
最尤法によるパラメタの推定値は、尤度関数を最大化するものですから、次のようになります。
$$
large
begin{align}
hat{theta} &= argmax_theta l(theta) \
&= argmax_theta Nlogfrac{1}{sqrt{2pi}sigma} – frac{1}{2sigma^2}sum_{i=1}^N (y^{(i)}-theta^mathrm{T} x^{(i)})^2 \
&= argmax_theta -frac{1}{2sigma^2}sum_{i=1}^N (y^{(i)}-theta^mathrm{T} x^{(i)})^2 \
&= argmin_theta frac{1}{2sigma^2}sum_{i=1}^N (y^{(i)}-theta^mathrm{T} x^{(i)})^2 \
&= argmin_theta sum_{i=1}^N (y^{(i)}-theta^mathrm{T} x^{(i)})^2 \
end{align}
$$
最後の行が、最小二乗法において最小化するコスト関数と同一であることが確認できます。すなわち、誤差項に同一の分散を持つ正規分布を仮定した線形回帰における最尤推定は、最小二乗法と等価である、ということです。
まとめ
今回は、データマイニングの最もシンプルな手法である線形回帰を例に、最小二乗法および尤度関数について説明しました。今回取り上げた線形回帰は「単回帰分析」と呼ばれ説明変数が1つの場合でしたが、次回の記事は重回帰分析(説明変数が複数)や、多項式によるフィッティングについて説明します。